

中文
 2026-03-30 11:41:14
2026-03-30 11:41:14



随着大模型从实验室走向产业化,存储系统已不再仅仅是数据的“仓库”,而是演变成了AI算力的“燃料泵”。从AI应用的视角来看,传统的存储架构正面临前沿业务逻辑带来的严峻挑战。
一、 AI应用的业务特性:训练与推理的双重挑战
AI业务流程对存储的要求呈现出极端的非对称性,我们需要分场景来看:
1. 模型训练阶段:追求极致吞吐与容量弹性
- EB级数据跨越: 多模态趋势下,训练集正从PB级向EB级跃迁,要求存储具备极致的线性扩展能力,突破传统文件系统的容量瓶颈。
- Checkpoint高频读写: 为防止训练中断,系统需频繁读写Checkpoint文件。这要求存储支撑每秒百GB级的写入和读取吞吐,以缩短算力等待时间。
- 生命周期管理成本: 全闪存方案在EB级规模下成本高昂。企业急需自动化分层技术,实现温、冷数据在闪存与机械硬盘间的智能流动。
2. 模型推理阶段:侧重低时延与快速检索
- 冷热数据瞬时切换: 随着AI融入生产(如代码助手、知识库),数据热度变化极快,要求存储能秒级激活温冷数据。
- 应用上线周期压缩: 为支持快速迭代,存储必须具备高效的数据预处理与检索性能,缩短数据准备耗时。
二、 市场现状分析:传统与分布式存储的瓶颈
目前的存储方案在应对AI原生应用时,普遍存在“架构错位”:
|
存储类型 |
核心架构 |
优势 |
AI场景下的瓶颈 |
|
传统存储 |
集中式/专用硬件 |
稳定、高性能 |
弹性扩展不足,难以应对AI瞬时爆发的容量需求。 |
|
分布式存储 |
Shared-Nothing (X86) |
易扩展 |
节点间网络同步开销大,IOPS与时延在超大规模下表现不及预期。 |
关键痛点:数据孤岛与品牌碎片化
大多数用户机房是“多品牌并存”的(如消费级NAS、传统全闪阵列并存)。目前市面上缺乏能统一纳管、跨品牌透明流动的数据管理能力。
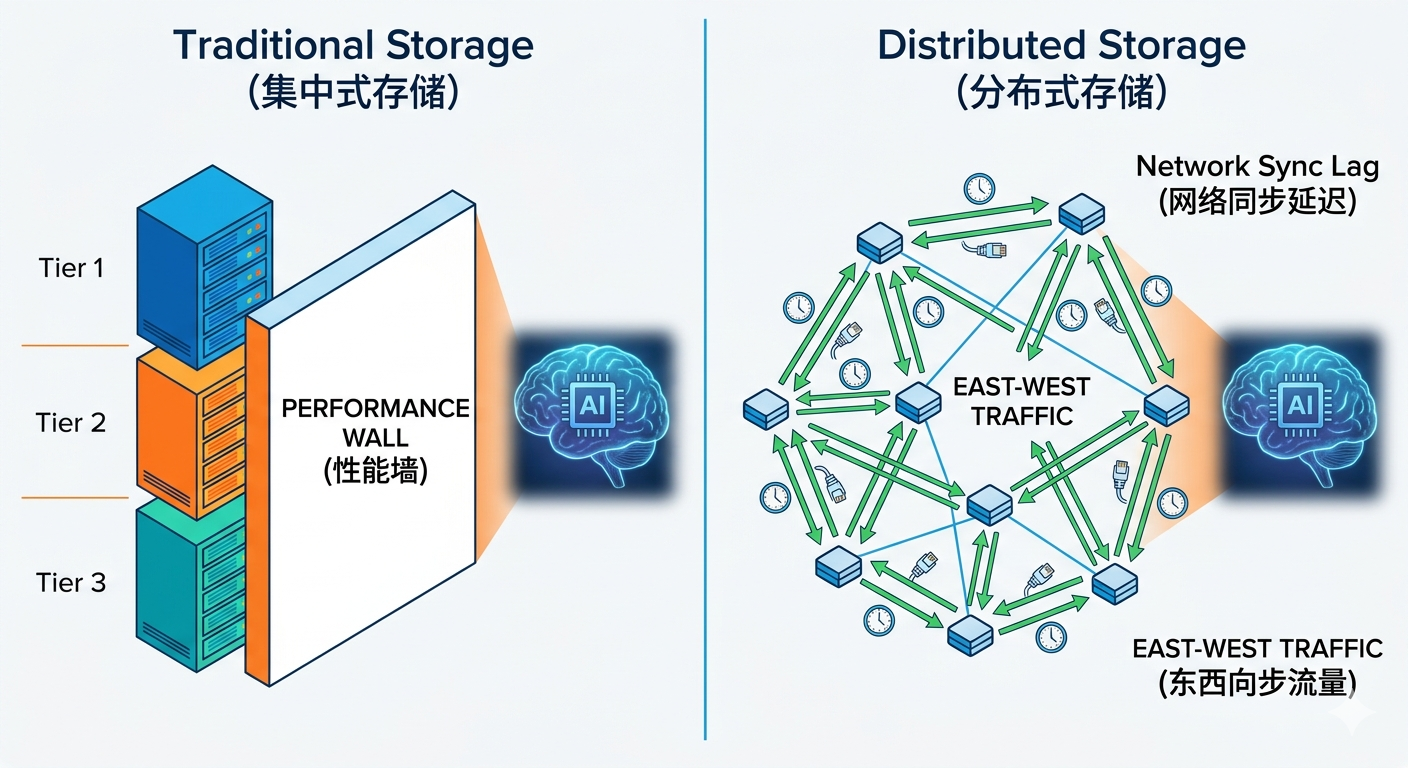
三、 进化方向:从 Shared-Nothing 到 Shared-Everything
要同时拥有传统存储的高性能与分布式存储的灵活性,架构演进是唯一出路。
Shared-Everything 架构的崛起
既然节点间通讯是瓶颈,那么构建一个**全共享架构(Shared-Everything)**的分布式存储就成了最优解。这种架构消除了节点间的性能损耗,提供了一致的高可靠与高性能体验。深信服EDS统一存储:为AI应用打造的数据引擎
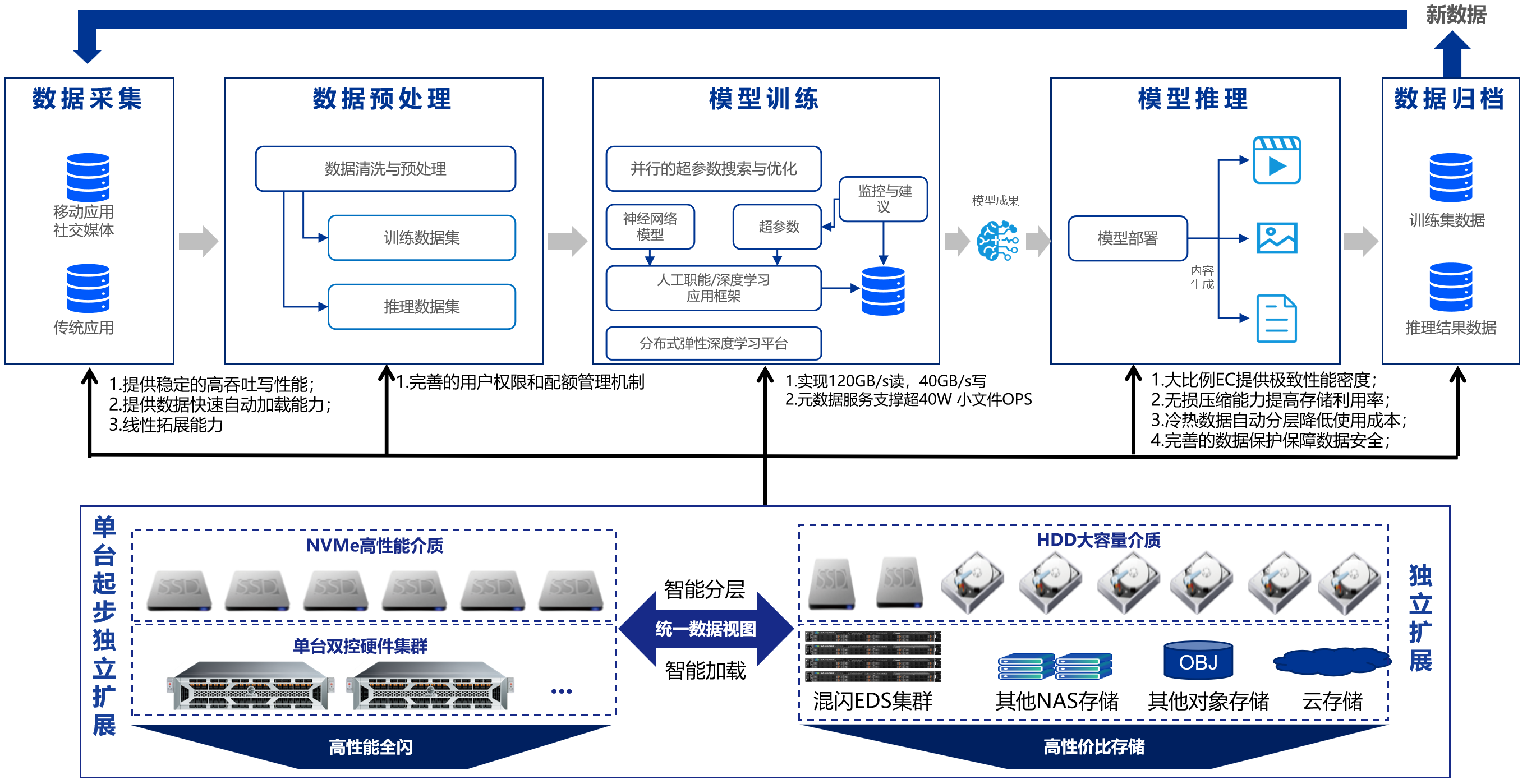
针对上述挑战,深信服推出了EDS统一存储,通过三大核心能力重新定义AI存储底座:
1. MMUA多模统一架构:实现真正的线性性能
EDS采用自研的 Multi-Mode Unified Architecture (MMUA)。通过Shared-Everything设计,彻底消除东西向流量对性能的干扰,让每一台新增节点都能贡献100%的性能增长。
2. 全局统一数据视图:激活沉默数据价值
EDS能够构建全局统一视图,将机房内多品牌、跨协议(NAS、混闪等)的存储统一纳管。支持温冷数据快速流动,为AI模型训练提供源源不断的“新鲜”语料。
3. 全生命周期智能管理:兼顾规模与成本
支持从闪存到混闪、甚至第三方云存储的自动分层或归档。EDS能够支撑从TB到EB级的任意规模数据,确保企业在享受AI红利的同时,存储成本依然处于最优曲线。
 总结
总结
AI时代的存储不应是算力的负担,而应是效率的倍增器。深信服EDS通过架构层面的彻底革新,正助力企业跨越AI落地的数据鸿沟。
扫码获取一对一服务

关注我们
关于我们


关于我们
扫码获取一对一服务

