

中文

 2026-03-25 15:54:27
2026-03-25 15:54:27



在上一篇《全球供应链风险加剧,IT基础设施如何从容应对价格变量?》中,我们探讨了在算力硬件紧缺、预算吃紧的大背景下,用户可以通过“老旧服务器资源优化路径,在极小性能损耗下,实现主机可用内存的翻倍。
这引发了不少用户的关注与探讨:突破物理内存的容量天花板,在技术上究竟是如何实现的?将存储介质作为内存使用,CPU 的访问延迟问题又该如何解决?
今天,我们将打开技术“黑匣子”,客观剖析深信服“内存分层技术”的底层实现逻辑、适用场景以及规划边界。
为什么内存可以“分层”?
在企业级内存优化领域,传统技术方案(内存气泡、透明页共享、内存压缩、内存超分等)均可以提升物理内存利用率,在一定程度上缓解内存压力,但提升幅度有限。当业务规模持续增长时,仍然需要新的技术手段来扩展系统可用内存容量。
在云原生与虚拟化环境中,应用(如 JVM、缓存服务、中间件)通常会预留大量内存空间,但真正频繁读写的活跃内存仅占 50% 左右,其余部分则处于低访问的冷状态。
基于这一核心特性,内存分层方案得以落地:将内存数据按访问热度划分为热数据层与冷数据层,通过物理 DRAM 与高性能 NVMe SSD 构建统一内存资源池,依托智能调度算法实现冷热数据的动态流转,在保障核心业务性能的前提下,突破物理内存的容量限制。
DRAM 与 NVMe 如何智能协同?
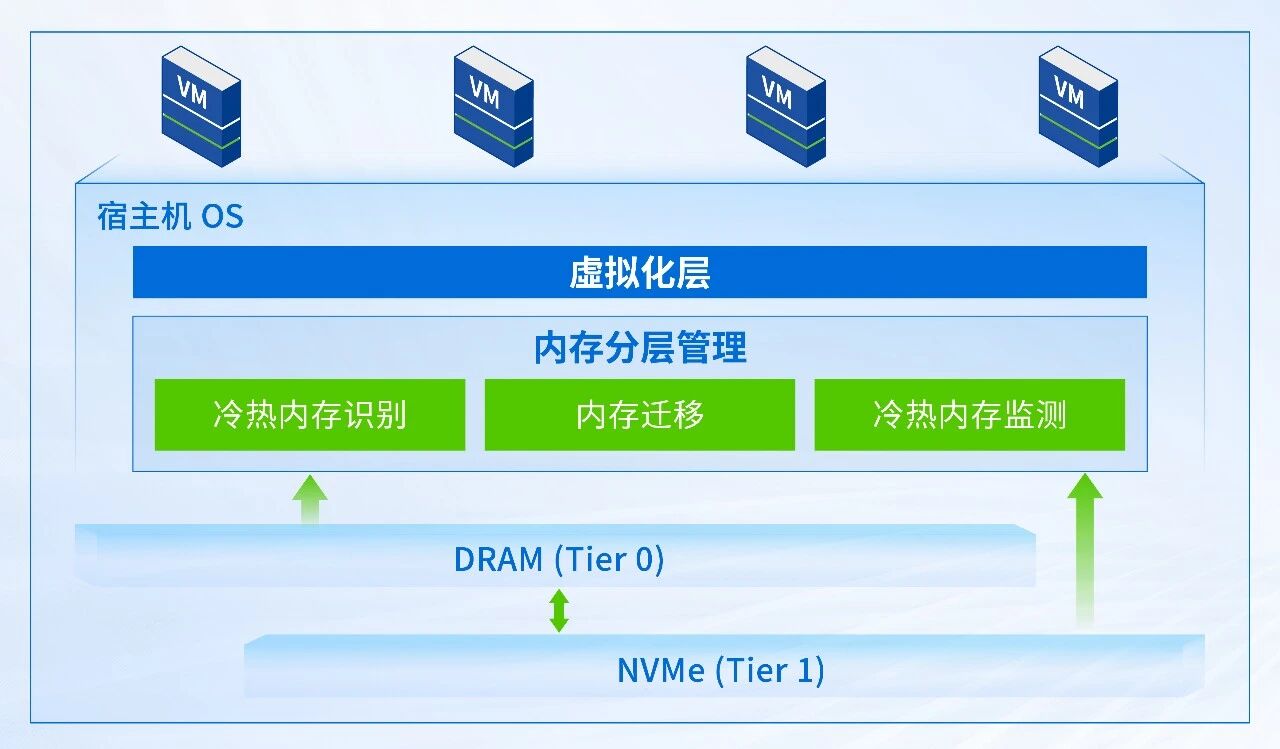
深信服内存分层方案,采用「多级内存池 + 智能调度引擎」的核心架构,实现 DRAM 与 NVMe SSD 的高效协同,在极低系统开销下完成内存的分层管理与动态调度。
01 多级内存池架构设计
Tier 0(热数据层):DRAM 承载高频访问、低延迟高敏感的热数据,是业务性能的核心保障;
Tier 1(冷数据层):高性能 NVMe,作为内存扩展层,承载低频访问数据,实现内存容量的弹性扩展。
02 智能调度引擎
智能调度引擎是内存分层方案的核心,通过「动态区域划分 + 随机稀疏采样」技术,以极低的系统开销获取全局内存的冷热分布,实现冷热数据的精准识别与动态调度。
核心包含三大能力模块:
-
冷热内存精准识别(找得准)
通过持续的热度探测,实时锁定业务真实的活跃工作集,精准区分哪些是必须留在高速 DRAM 的热数据,哪些是可下沉的冷页面 。
-
内存自动化迁移(挪得快)
自动化执行数据的“冷下沉”与“热回迁”——释放 DRAM 空间给核心业务,同时确保重新活跃的数据能瞬间回到热层,保障访问性能 。
-
全链路可监测(看得见)
持续监控内存冷热分布、页面迁移行为以及冷层访问情况,形成完整的可观测能力。通过监控数据帮助运维识别潜在性能风险,并为策略优化与容量规划提供依据。
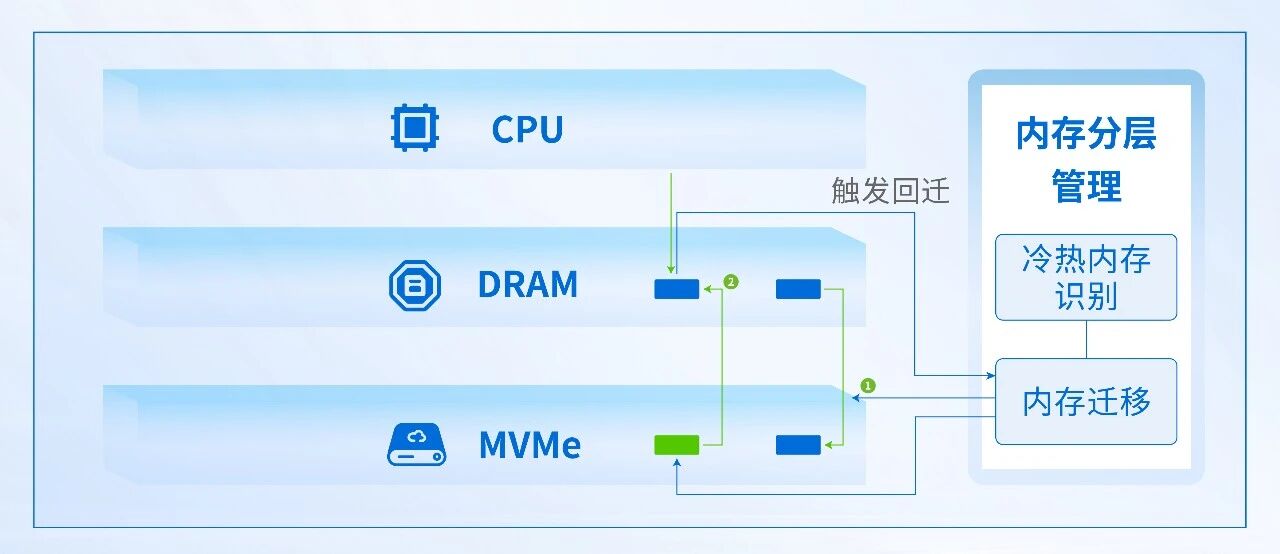
03 DRAM 与 NVMe 冷热数据流转
DRAM→NVMe 冷页下沉流程
当系统识别出低访问频率的冷页后,将其纳入冷页迁移候选队列。系统为目标页面分配 NVMe 冷层存储位置,将页面数据从 DRAM 写入 NVMe SSD,同步更新内存映射关系。完成迁移后,释放该页面对应的 DRAM 空间,实现高速内存资源优先用于承载活跃数据。
NVMe→DRAM 热页回迁流程
当业务重新访问已下沉至 NVMe 冷层的页面时,系统会实时捕获该访问请求并触发回迁流程;将目标页面数据从 NVMe读取回 DRAM,同步更新内存映射关系,让重新活跃的数据进入高速内存层,恢复正常访问性能。
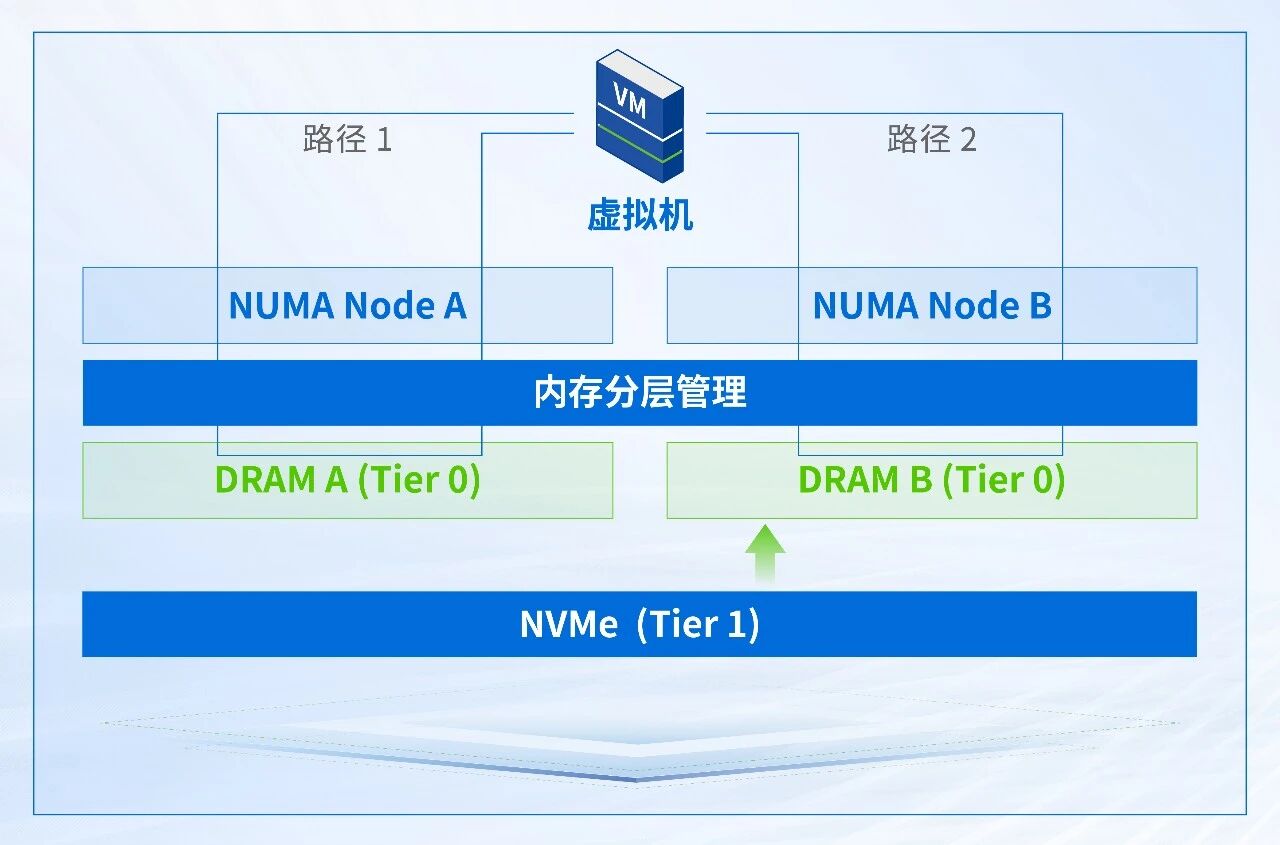
CPU 如何访问分层内存?如何做到性能损耗较小
内存分层的技术难点在于,冷热数据如何快速识别、冷热页调度以及内存分层以后,CPU如何快速访问内存。
在内存分层体系中,NVMe 设备并不是传统意义上的存储,而是作为 DRAM 之下的冷内存层(Cold Memory Tier) 使用。因此,服务器CPU访存操作均基于 DRAM 完成。
其核心分为两种访问路径:
路径1:热页命中
CPU 发起访问→本地/远端 DRAM →返回数据
路径2:冷页未命中
CPU 发起访问→目标页不在 DRAM 热层→系统将该页从 NVMe 调回 DRAM → CPU 再访问该页
既然服务器CPU并不直接访问NVMe ,是如何做到对性能影响较小的呢?
针对用户对分层后性能的疑虑,系统通过以下逻辑确保业务运行的确定性:
-
统一地址空间 + 透明访问,对应用无感知
当访问DRAM 中的热页,直接命中,无额外开销。当访问NVMe 中的冷页,触发缺页中断,内核把数据从 NVMe快速拉回 DRAM,再让 CPU 访问。底层由OS 内核管理,CPU 访问时,完全不知道数据在 DRAM 还是 NVMe,由内核判断并处理。
-
冷热数据智能调度,动态区域实时调整
系统会根据监控结果动态调整区域结构,以平衡监控精度与系统开销。当相邻区域的访问模式相似时,会自动合并区域以减少监控对象数量;当检测到区域内部存在明显的访问热点时,则会对区域进行分裂,从而实现更细粒度的热点识别。通过区域合并与分裂的自适应机制,使监控系统始终保持合理的监控粒度。
-
低延迟 NVMe把中转开销压到最低
NVMe 控制器通过 PCIe 直接读写 DRAM,无需 CPU 干预,仅占少量 CPU 中断资源。
NVMe 硬件优势:延迟:10–100μs(远低于 SATA SSD / 机械盘)。
带宽:PCIe 4.0 NVMe 可达7GB/s,接近 DRAM 的 1/10,远高于传统存储。
内存分层能做到性能影响极小,核心是靠对应用透明管理 + 冷热数据智能调度 + 低延迟 NVMe,让 CPU 始终在高速路径上工作。结合内核 IO 路径优化与原有 NUMA 本地亲和特性无缝继承,整机内存容量翻倍,实测性能下降稳定控制在 10% 以内。
落地实践指南:业务适配场景与规划建议
01 业务适配场景
适配业务场景
内存分层技术适用于内存总容量需求大、数据访问呈现明显冷热特征、对成本敏感且可容忍轻微偶发延迟的业务场景。
例如:桌面云平台、开发测试环境、非核心缓存服务、中低负载微服务集群等。
非适配业务场景
内存分层不适用于对访问延迟极度敏感、数据访问密集且均匀、要求严格低抖动与高稳定性的核心业务场景。
例如:实时交易系统、高频交易数据库、内存数据库、高频 OLTP 数据库等。
深信服内存分层方案,支持虚拟机颗粒度的功能启停。用户可根据不同业务的类型与特性,灵活开启/关闭对应虚拟机的内存分层能力,实现性能与成本的精细化管控。后续硬件价格回落,可无缝在线加配扩容,投资无锁定、演进无后顾之忧。
02 最佳内存分层规划
为平衡内存扩展效果与业务性能稳定性,建议 DRAM:内存分层容量=1:1。该比例可覆盖绝大多数企业级业务场景的需求,在实现内存容量翻倍的同时,将业务性能波动控制在可接受范围内。
在内存硬件价格持续高企的市场环境下,内存分层技术不再是单纯的性能优化手段,而是一套行之有效的成本控制战略。用户可在不牺牲核心业务性能的前提下,大幅削减内存硬件采购预算,最大化现有 IT 资产的复用价值,从容应对业务算力增长与 IT 成本管控的双重挑战。
扫码获取一对一服务

关注我们
关于我们


关于我们
扫码获取一对一服务

