

中文

 2026-04-22 11:57:15
2026-04-22 11:57:15



当我们谈论千亿参数大模型与DGX H100的恐怖算力时,往往忽略了一个扎心的事实:GPU饥饿问题。
想象一下,你手握着F1赛车级别的GPU算力,引擎马力十足,但数据“油路”却只有家用轿车的水平。底层的存储协议栈,正在拖算力的后腿。
在此背景下,存储系统的性能,决定了AI能否高效运行。
为何说S3对象存储+RDMA 是AI时代的标准答案?
随着AI大模型多模态发展,训练数据量从TB级跃升至PB级甚至EB级,这对存储系统提出了前所未有的挑战。
AI业务的本质不是简单的文件读写,而是海量多模态语料的流式吞吐。而对象存储天然具备AI Native时代的基因,正成为新一代AI存储的重要技术方向。
- 无限扩展能力:采用扁平命名空间设计,天然支撑海量多模态语料。
- 生态开放兼容:PyTorch / TensorFlow / Spark 等主流AI框架,全链路支持S3 API流式加载。
- 全生命周期覆盖:从原始数据集的数据湖,到模型训练的加载,再到推理环节向量数据库的底座,S3 API已成为贯穿AI全生命周期的事实标准。
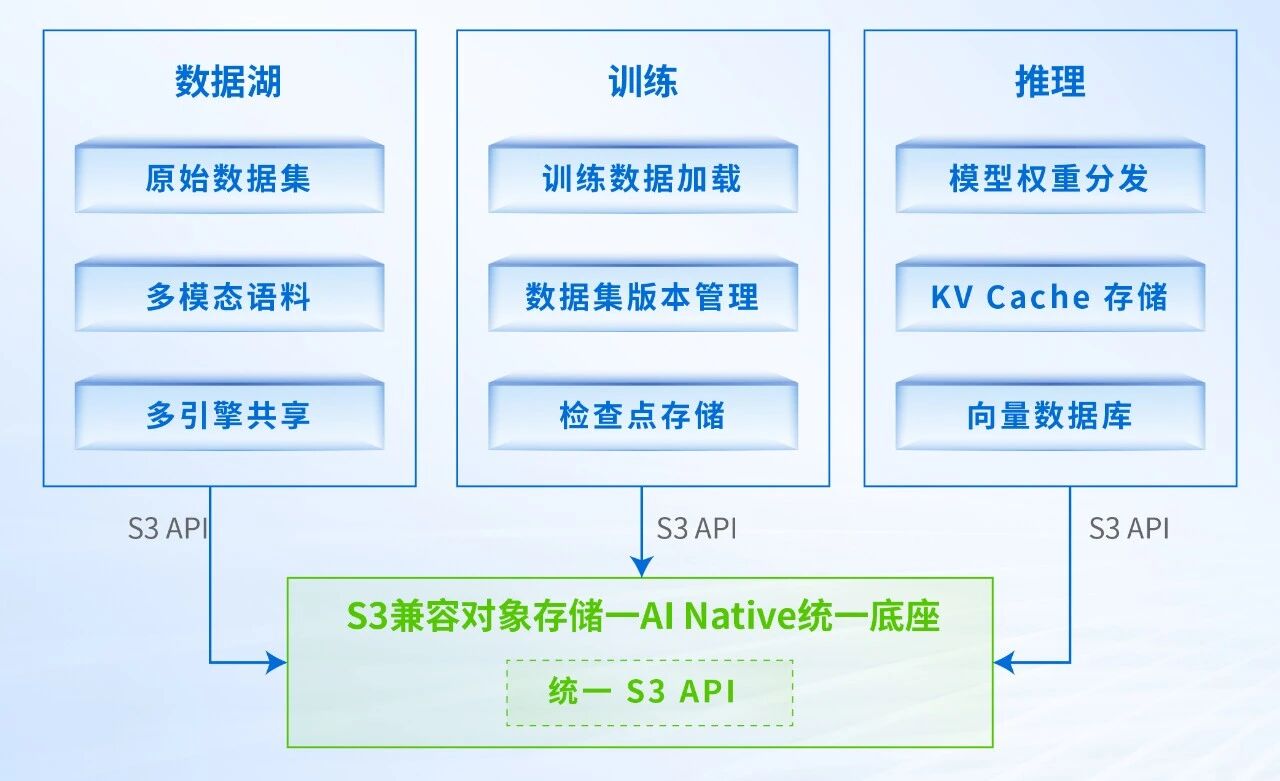
AI全生命周期×对象存储
然而,在传统的S3对象存储架构下,数据要先经过内核协议栈,由CPU进行TCP解包,拷贝到系统内存,再经由CPU搬运到GPU显存。
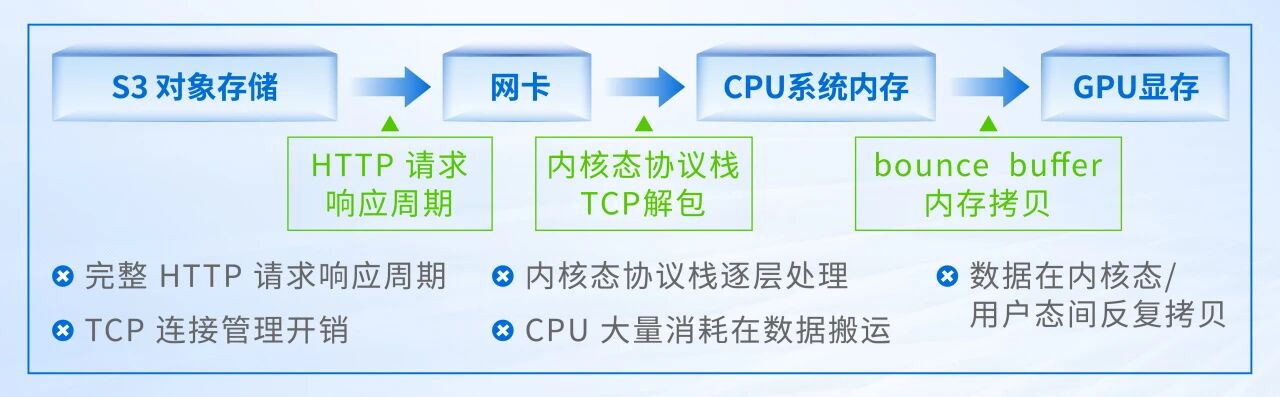
传统S3 over TCP数据路径
在这个过程中,CPU既要负责协议解包,又要负责内部搬运,延迟高达毫秒级,导致GPU因频繁等待数据而在“空转”,算力利用率低下。这是对象存储在性能上的弱势——数据供给速度无法匹配GPU处理需求,如同扼住了GPU的“咽喉”,成为制约整个系统发展的瓶颈。
如今,对象存储最后的性能短板也被彻底补齐了。2026年1月,NVIDIA cuObject (GPUDirect Storage for Objects) 正式发布,打通数据传输的“最后1公里”——让S3对象存储具备RDMA高性能数据通路。
S3对象存储+RDMA的两大技术路线
针对不同的计算生态,目前业内形成两条互补的S3对象存储+RDMA技术路线,确保每一份数据都能以微秒级延迟抵达应用场景。
GDS for Objects:NVIDIA GPU存储直通
对于纯粹的NVIDIA GPU训练与推理场景,cuObject是最优解。
- 技术逻辑:实现控制面与数据面分离。S3指令走标准HTTP,但核心数据负载通过RDMA直传,完全绕过CPU。
- 核心价值:物理地址经PCIe BAR暴露,网卡DMA直接将数据写入GPU显存。这不再是“RDMA到主机内存”,而是真正的“RDMA直达GPU显存” 。
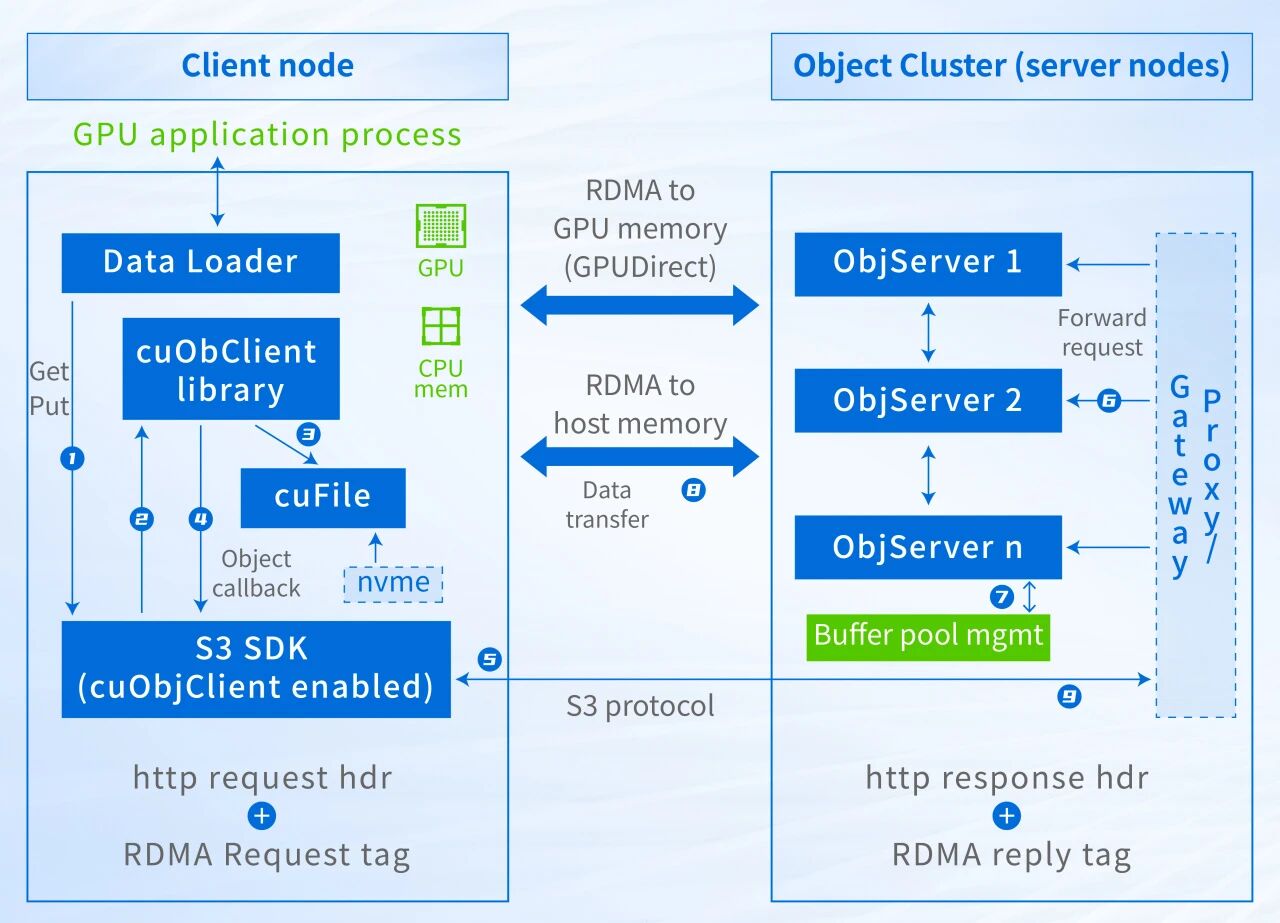
GDS for Objects实现方案
S3 over RDMA:通用计算绕过CPU直接访问内存
AI基础设施不只有GPU,还有大数据分析(Spark)、特征工程等CPU密集型任务,或者国产化异构集群。
- 技术逻辑:用RDMA替代传统TCP承载S3传输,将数据面从内核协议栈卸载到网卡硬件。
- 核心价值:数据绕过内核态拷贝,直接进入应用预注册的用户态主机内存,且不绑定任何特定计算厂商,具备极强的普适性。
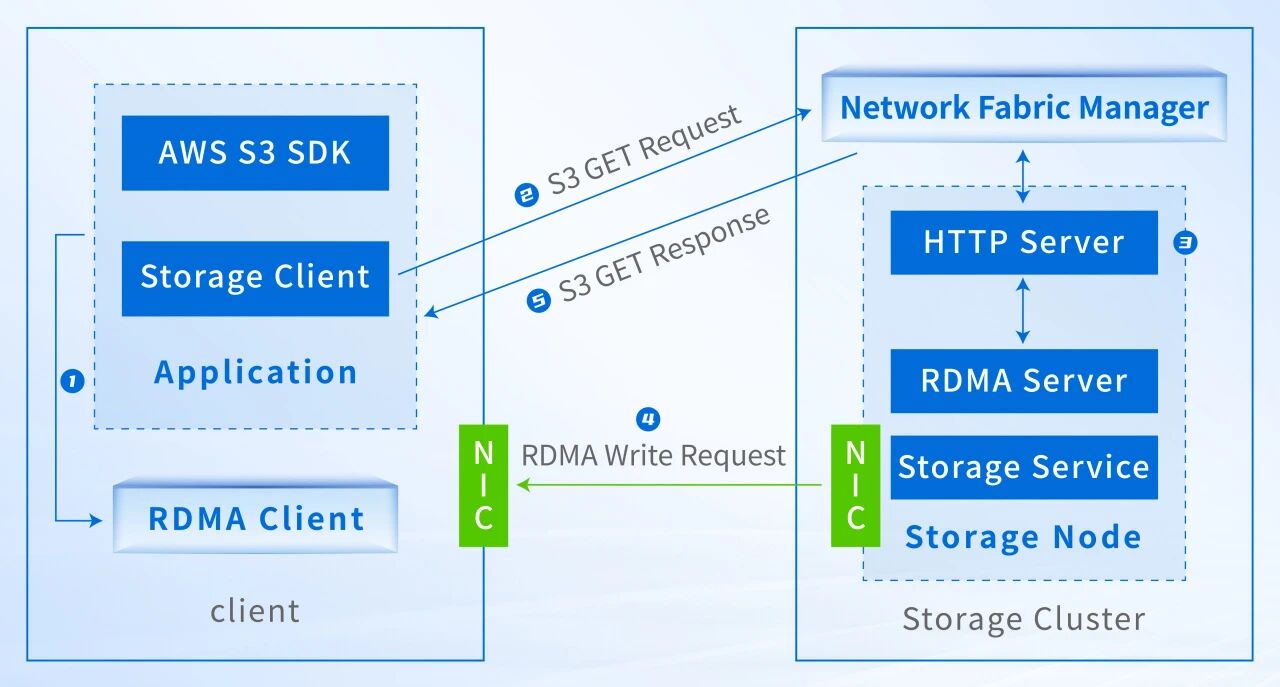
典型S3 over RDMA实现方案
如何突破全链路性能瓶颈?
RDMA只是起点,要真正实现工程落地、跑出性能上限,必须在存储引擎上“动大手术”。
深信服通过三大关键技术突破全链路性能瓶颈:
关键技术一:SPDK全用户态存储栈
传统存储栈运行在内核态,每次I/O都要伴随系统调用和上下文切换。这在微秒级延迟的RDMA面前,就是巨大的浪费。基于SPDK打造全用户态路径:从请求接收到NVMe SSD落盘,全程在用户态完成。
关键技术二:端到端零拷贝
为了消除每一处不必要的内存搬运,在三个环节贯彻零拷贝:
- 节点内:S3服务与存储引擎通过共享内存传递数据。
- 节点间:集群内部通过RDMA传输,网卡直接从共享内存读写。
- 介质访问:SPDK驱动将共享内存直接提交给SSD控制器。
最终,数据从SSD到GPU显存,全程只存在一份。CPU彻底被解放出来,去做更重要的计算任务。
关键技术三:目录桶语义
标准S3协议在写入时要计算MD5(ETag),在高吞吐下非常吃CPU。通过类似AWS S3 Express One Zone的“目录桶”语义,支持禁用ETag计算并简化一致性模型,进一步卸载协议层开销,完美契合AI训练的大批量写入场景。
实测读吞吐120GB/s,性能跃升2.63倍
纸上得来终觉浅,数据才是硬道理。
针对上述三种技术路线,深信服在内部环境下进行性能实测。
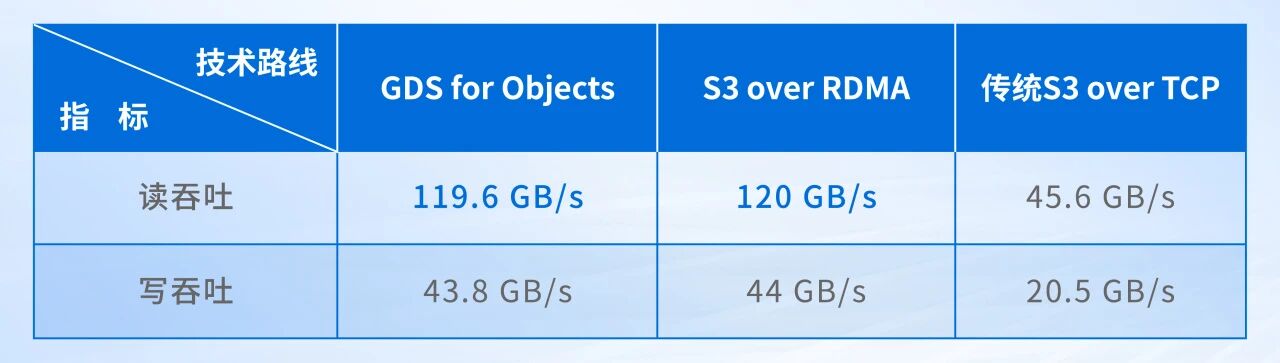
相较于传统S3 over TCP,通过RDMA加持的读吞吐提升至原来的2.63倍,写吞吐是原来的2.14倍。单节点百GB级的带宽,可以更加从容地应对千亿参数模型的Checkpoint读写和海量语料加载。
由此可见,对象存储已经系统性地突破了AI核心数据通路的最后一道“性能瓶颈”。S3对象存储+RDMA将成为AI时代的标配,凭借高吞吐、低延迟与近乎无限的扩展能力,完美匹配大模型训练、推理与多模态数据洪流,全面接管AI数据湖与训推存底座。

备注来自“深信服官网”
扫码获取一对一服务

关注我们
关于我们


关于我们
扫码获取一对一服务

