

中文

 2026-05-16 11:48:38
2026-05-16 11:48:38



硬件涨价潮下,如何在有限预算内完成业务上线?先通过“腾挪”盘活存量资源,再配合按需“新购”补缺。用小幅预算增量化解成本压力——正是当下用户穿越供应链承压期的务实选择。
本文面向已拥有存量服务器资产(无论是裸金属、VMware/国产第三方平台,还是深信服超融合平台),急需扩容但因硬件涨价预算吃紧的用户。提供资源利旧的一站式实操指南,涵盖:“资源评估 → 方案设计 → 资源腾挪整合 → 服务器改造 → 集群部署上线”,以期帮助用户从现有资源中“抠”出新空间,无需大幅追加预算,快速上线新业务。
01资源评估——摸清家底
评估目标:搞清现有平台能腾挪出多少资源,确认旧服务器能否利旧、扩容。
智能评估
深信服提供以下智能工具和专家服务:
智能工具诊断 1:AI 资源瘦身评估
基于机器学习分析虚拟机负载,智能识别超配虚拟机(资源远超实际使用)与僵尸虚拟机(闲置无人用),输出安全降配清单与可释放资源预测。
智能工具诊断 2:自动化硬件体检
扫描核验旧服务器及配件兼容性,提前排查内存 UE/CE、网络亚健康、磁盘 IO 异常等隐患,避免问题在业务运行阶段暴露,保障核心业务平稳运行。
智能工具诊断 3:VMware活跃内存评估
VMware虚拟机活跃内存数据,评估超融合内存分层可节省的资源,并输出报告展示各虚拟机活跃内存、阈值及可释放总量。
人工专家诊断 4:定制化落地闭环
专属专家团队结合评估报告,提供从资源腾挪到高可用配置的完整方案设计。
** 用户需提前准备:虚拟化管理平台的 API 和 SSH 访问凭证(评估工具需要同时访问两者)
02专业报告——存量腾挪、按需增购
“体检”完成后,用户会得到三份核心报告:
-
超配虚拟机减配清单:识别CPU/内存配置远超实际使用量的虚拟机,含历史运行数据与未来趋势,输出可缩减的资源量。
-
僵尸虚拟机清单:统计闲置虚拟机数量,计算关闭后可释放的资源量。
-
硬件兼容性检测报告:覆盖服务器、CPU、内存、磁盘、RAID卡、HBA、GPU、网卡、外接存储等,确认旧服务器能否直接利旧部署。
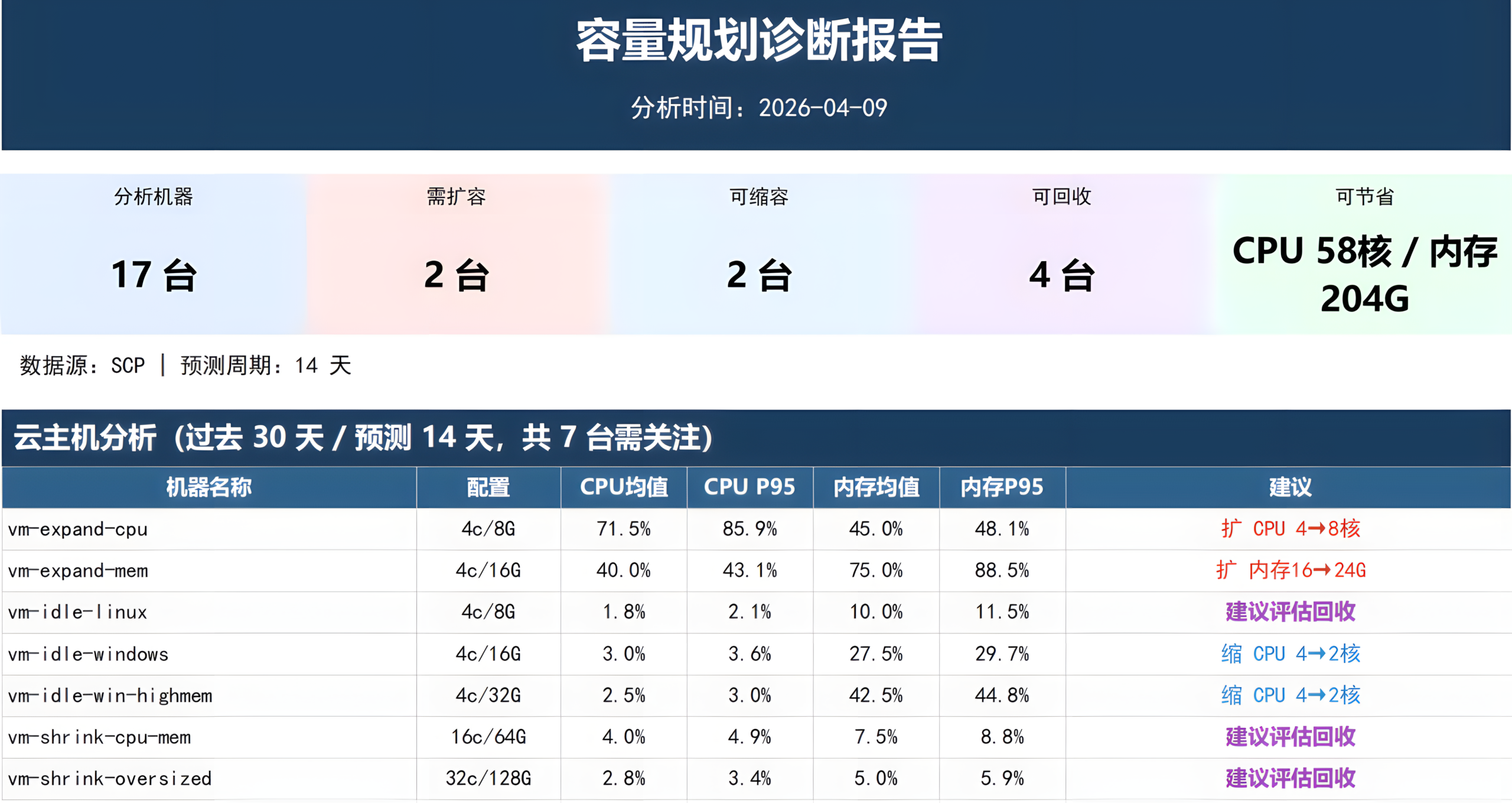
根据以上评估报告,用户即可明确能腾挪出几台服务器,还需要新购几台服务器,有效降低成本,解决原预算大幅上涨项目无法继续执行落地的问题,从而制定精准的采购计划。
03资源整合腾挪
虚拟机及配置调整
僵尸虚拟机:先关闭虚拟机网络隔离观察一段时间,如果没有业务部门反馈,再执行关机处理,逐步释放计算资源。
超配虚拟机:在与业务部门或平台运维方充分沟通确认后,按需优化资源配置(评估工具会给出可以缩减的资源量--预留了虚拟机未来增长的余量)。
宿主机之间虚拟机调整,腾出物理机服务器
腾挪时需要考虑以下因素:

** 建议全部操作通过平台热缩容功能执行,安排在夜间低峰期进行,业务无感知。
04服务器改造
腾挪出的物理服务器需要进行两项关键改造:
超融合节点改造
根据超融合平台部署要求,补充必要的硬件组件,包括缓存盘、数据盘以及万兆网卡等关键配件,以满足存储性能与网络带宽要求。
内存分层能力改造
为进一步提升资源利用效率、降低整体建设成本,通过在服务器中新增 NVMe SSD,构建高性能的内存分层存储层,实现冷热数据分层管理。
在标准生产场景下,深信服建议采用 DRAM 与内存分层容量 1:1 的配置策略,在保障业务性能的前提下,实现性能与成本的平衡优化。
为保障系统高可靠性与稳定运行,推荐选用符合以下要求的 NVMe SSD:
-
采用企业级读写混合型NVMe SSD;
-
磁盘性能:写入性能 ≥ 100K IOPS;
-
磁盘寿命:建议选择 D 级或更高等级产品(≥ 7300 TBW)。
05集群部署与最佳实践设置
经过前期的资源评估与腾挪,利旧资源清单已明确,硬件兼容性与亚健康问题已完成排查;同时,针对利旧集群的性能瓶颈和代次缺口,制定了精准的新购补充计划(如NVMe SSD、万兆网卡或服务器)。
至此,利旧资源与新购资源均已就位。接下来,我们将两者融合为一个统一的HCI集群,用于承载核心业务的稳定运行。
实施路径分为两步:
集群部署
支持aDeploy工具或者PXE批量部署HCI系统,将利旧服务器组建为HCI集群(服务器CPU代差要求在3代及以内)。
可靠性最佳实践配置
利旧集群的核心挑战在于:老旧设备的物理可靠性天然低于新设备。因此,整个方案能否成功,最终取决于软件定义的可靠性机制能否有效弥补物理层面的不足。
在完成纪元检测工具对硬件亚健康扫雷后,交付工程师将遵循可靠性最佳实践配置利旧服务器集群,提升其可靠性保障。
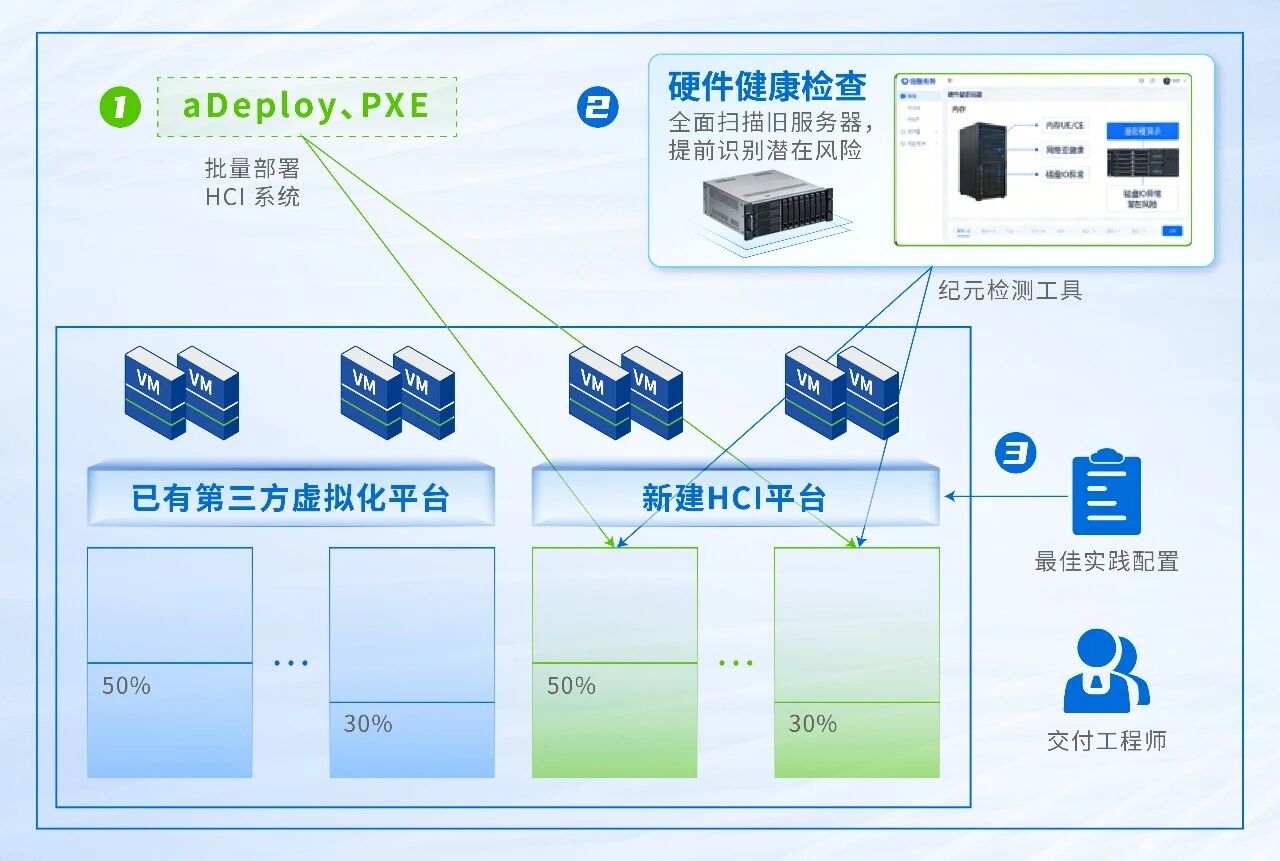
硬件亚健康主动检测与处置
提供覆盖网络、磁盘、CPU、内存及外置存储的全维度硬件亚健康检测与处置机制——其中内存技术通过主动扫描隔离错误块、处理CE/UE错误保障业务稳定;磁盘坏道预测借助算法模型将发现时间从数周缩短至一天,并结合aSAN实现数据重建闭环,以软件冗余有效弥补老旧硬件的物理缺陷。
HA 2.0高可用保障
深信服HA 2.0通过主动检测CPU微码、温度、内存ECC、系统盘寿命、电源等亚健康状态,在执行智能热迁移前完成资源预调度,从根源保障业务连续性。
云端专家兜底服务
“云端智能管家” 7×24 小时在线值守,提供可靠性兜底服务。线上平台实时监测、专业工具精准预警、专家团队远程 “会诊”,三重保障加持,主动识别全栈风险、秒级响应处置,让业务运行全程安心。

*实操避坑小Tips
-
超配虚拟机减配必须先沟通业务方,不可直接修改配置;
-
内存分层 NVMe磁盘严禁与 aSAN 分布式缓存盘混用,否则会导致性能下降;
-
硬件改造前建议用纪元工具做健康检查,排除亚健康硬件;
-
资源腾挪务必在业务低谷执行,避免影响用户。
扫码获取一对一服务

关注我们
关于我们


关于我们
扫码获取一对一服务

