

中文

 2026-05-29 20:03:19
2026-05-29 20:03:19



2025年Gartner曾发出一则警示:60%的AI项目将因缺乏AI-Ready数据而被放弃。
复盘近两年落地失败的AI知识助手、智能客服系统项目,同样会发现:模型没毛病,数据有毛病。
随着Agent应用的集中爆发,整个AI产业链在加速发展,对企业数据基础设施提出了全新要求。想要支撑Agent自主运行与业务智能运营,企业亟需搭建AI-Ready数据底座。
这也意味着,企业数据平台迭代迫在眉睫,数据湖必须从湖仓一体(Lakehouse)演进为AI数据湖——在湖仓一体的基础上进一步迭代,同时承载分析与AI负载,加速模型训练与推理的效率。
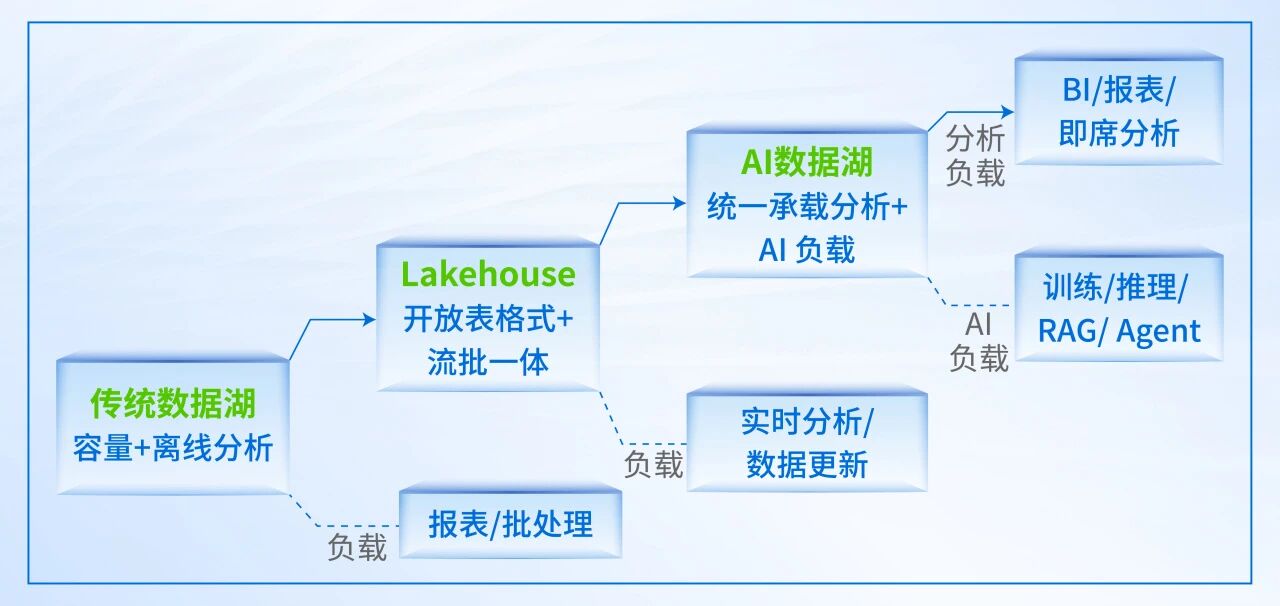
从传统数据湖到AI数据湖的演进过程
数据湖在AI时代面临的三重挑战
在AI深度赋能业务创新的当下,传统数据湖的建设方式面临诸多挑战,难以满足AI训练与推理、实时分析等需求。
分析侧:存算紧耦合,查询响应慢
大量企业在部署数据分析业务时,依然是按照业务需求采用烟囱式的建设方式——一个业务一套系统,一套系统融合了计算与存储,导致基础设施处于存算紧耦合状态,即使没有AI,分析负载本身也在挑战这套架构。
- 扩展难:业务增长时,计算与存储必须同步扩容,成本按倍数放大,但性能特别是存储性能的提升大打折扣。
- 共享差:同一份数据要被BI、即席查询、机器学习样本仓共用,但每一处都要复制和重新治理。
以互联网即席查询场景为例,分析师在仪表盘上切换日期范围或维度,期望“点一下立刻出结果”。但底层数据分散在多个引擎和存储中,每次跨源查询都要拉取数据、转换格式、对齐时间窗——查询时间从“秒级”变成“分钟级”是常态。
业界常见的应对方式是增加各种数据缓存来提升性能,实现秒级返回。但这反而增加了复杂度:缓存与底座之间需要额外的协调机制来保证数据的一致性与可靠性。
AI训练侧:异构算力等数据,GPU利用率被拖累
一次完整训练涉及PB级多模态语料的持续加载、亿级小文件的随机访问、TB级Checkpoint的高频写入。任何I/O等待,都会被折算成昂贵的GPU空转。
2024年微软对400个真实深度学习作业的研究显示:约46%的低GPU利用率问题与数据操作有关,如数据加载、存储访问和小文件处理效率差,导致数据供给跟不上。
更难的是多模态:训练侧需要同时消费文本、文档、图像、视频、音频、向量索引。已有架构往往需要为每种模态新建一套数据流。训练前还要反复ETL搬运、整理、转换,GPU就只能空转,迭代速度变慢,训练成本被推高。算力越多,空转浪费问题越凸显。
AI推理侧:数据不新鲜,AI回答就不可信
像智能客服、运维助手这类RAG应用,用户关注“回答准不准”。如果AI看到的是旧数据、残缺数据,结果自然是不靠谱的。推理侧拼的不只是模型能力,更是数据能否快速共享、及时可用。
虽然数据湖现有的Catalog服务(Hive Metastore / Iceberg Catalog / Unity Catalog等)提供了数据治理和发现能力,但是完整集成这套体系的成本和适配复杂度都高。
更重要的是,Catalog体系本就是面向分析与合规场景设计的,注重Schema演进、SQL权限、审计追溯。这与AI场景下“快速圈选数据、新数据立即可见、数据集版本可回溯”的诉求存在明显分歧,难以满足Agent实时数据可见性的需求。
如何搭建AI数据湖,实现数据Ready?
要化解上述三重挑战,企业需要一个全新的数据底座,可从三方面重点发力。
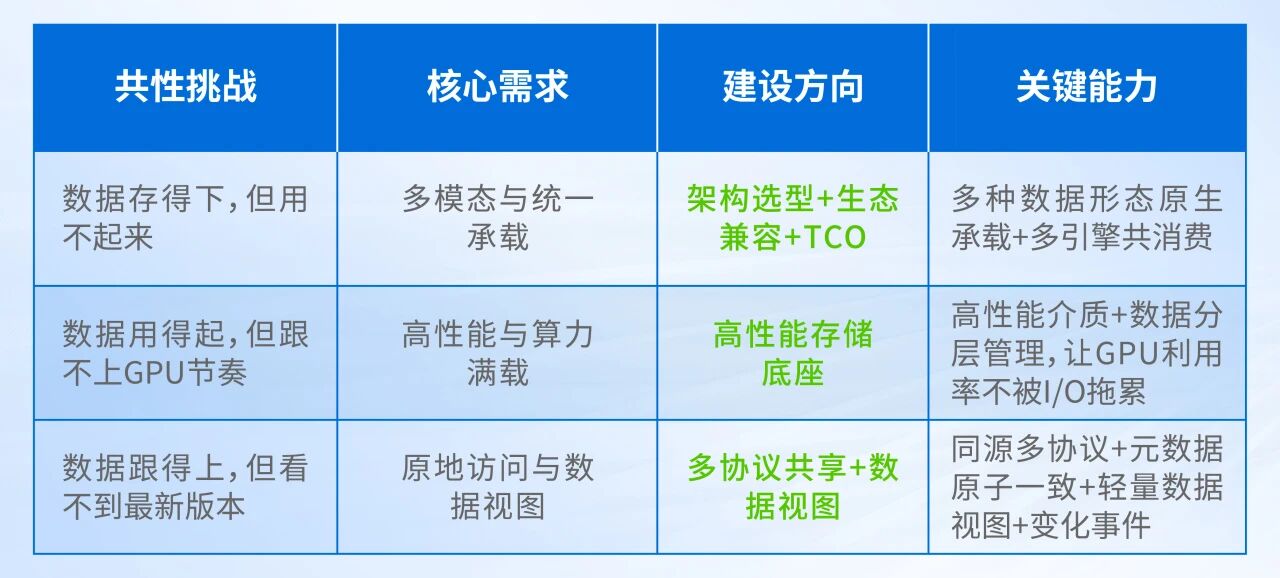
架构选型:存算分离+生态兼容+TCO
首先在架构上选择存算分离。选择可实现PB级向EB级扩展的存储底座,支持海量数据,且性能随规模同步扩展,为未来的AI落地打下坚实基础。
其次坚持生态兼容性。数据格式上,支持结构化、半结构化、非结构化等数据类型,兼容开放表格式;业务承载上,支持训练(PyTorch / TensorFlow 等)、推理(TensorRT / vLLM 等)、数据预处理(Spark / Ray)、向量检索(Milvus)、以及分析(Trino / Presto)等多种引擎共用。
最后考虑TCO与已有投资复用。运营成本和已有投资需要纳入选型考量中:能否复用已有存储设备、支持数据从老系统纳管和迁移到新底座,避免建一套AI数据湖等于扔掉以前所有投资。
高性能存储底座:做好数据分层管理
高性能介质(如全闪存)正成为AI数据湖底座的事实选择。在选型时,除了介质指标外,更应该结合业务负载验证:分析、训练、推理过程中存储是否成为瓶颈?GPU利用率是否被压低?
在数据管理方面,做好数据分层,让频繁访问的数据始终存储在高性能介质。对于历史分析数据、训练数据集、过期模型版本和标注数据等低性能要求的数据,保存到HDD机械硬盘或低成本存储(包括已有老旧设备);将全闪存储的容量集中用在对性能最渴求的业务环节。
数据实时可见:多协议共享与数据视图
一份数据原地承载,不再为不同应用复制副本,同时支持文件、对象等多种协议对同一份数据的访问。新数据落入底座后,对所有应用立即可见;数据变化(新增、更新、删除)能被轻量数据视图(类似Catalog)实时捕获,避免AI看到的数据已经过时。
具体落地时,企业数据存储应具备以下能力:
同一份数据多协议共享
同一个对象既能通过S3 API被训练框架读取,也能通过POSIX被传统应用读取。
元数据与数据原子一致
写入即可见,多协议视角下的元数据视图保持同步。
轻量数据视图
存储侧原生提供集合、视图、标签的轻量元数据管理,支持按namespace/tag快速圈选数据集,不依赖外部重型Catalog服务。
数据变化事件可订阅
当数据新增、更新、删除时,系统以事件形式推送给下游应用(RAG索引、训练Pipeline、Agent工具),让“实时可见”真正落地。
数据集版本快照
任意时间点可创建轻量快照,记录“这次训练用了哪个版本”,支持可回溯、可复现,简化数据集管理。
展望未来 数据不止于存储,更要被AI持续用起来
未来企业的核心竞争力,不在于谁的模型更大,而在于谁能更快、更稳地把数据转化为AI能力。
湖仓一体(Lakehouse)解决了一份数据如何被多种引擎分析的问题,而AI数据湖则进一步解决了一份数据如何被多种AI负载持续消费、持续沉淀的问题,最终形成AI-Ready数据底座。
放眼未来,当业务应用全面走向AI原生时,BI分析能力被集成到Agent工具集里,SQL查询变成大模型在后台自动调用。业务负载也将进一步收敛:分析负载被Agent负载吸收,最终留下的只有“数据底座”和“AI应用”两层核心结构。
而AI数据湖,正是这一收敛过程的关键起点。
参考资料
1、Gartner(2025): 60%的AI项目因缺少AI-Ready Data而被放弃,https://www.gartner.com/en/newsroom/press-releases/2025-02-26-lack-of-ai-ready-data-puts-ai-projects-at-risk
2、Microsoft Research / ICSE 2024:GPU利用率低的问题中约46%与数据操作有关,https://www.microsoft.com/en-us/research/uploads/prod/2024/01/gpu-util-icse2024.pdf
扫码获取一对一服务

关注我们
关于我们


关于我们
扫码获取一对一服务

