

中文

 2026-06-29 18:28:51
2026-06-29 18:28:51



进入2026年,对象存储侧的元数据能力出现了一个值得关注的变化:Amazon S3 Metadata 将对象元数据以 Apache Iceberg metadata tables 的形式暴露出来,使得分析引擎能够像查询普通表一样查询对象级元数据。
这次更新的核心意义,并不在于 S3 增加了一个元数据功能,而在于它释放了一个更为底层的信号——数据湖 Catalog 正在从“只管理已注册表”,扩展到“感知真实存在的数据资产和变化”。
过去谈到数据湖 Catalog,其核心问题通常是:这张表在哪里,Schema 是什么,谁有权限访问,血缘从哪里来、影响哪些下游。
现在,AI 工作负载进一步放大 Catalog 的问题。
AI 训练会产生大量非表数据,Agent 在运行时会执行一系列连续动作:选择非表数据源、检索上下文、调用工具、判断数据是否完整、决定下一步动作。治理系统也不再只是“给人看报表”,而是要持续发现异常数据、过期数据、权限变化和下游影响。
这意味着,AI 数据湖需要的已不只是表目录,而是一套更为完整的统一视图——能够明确数据在哪里、什么时候变化、在业务上代表什么含义,以及会影响哪些下游。
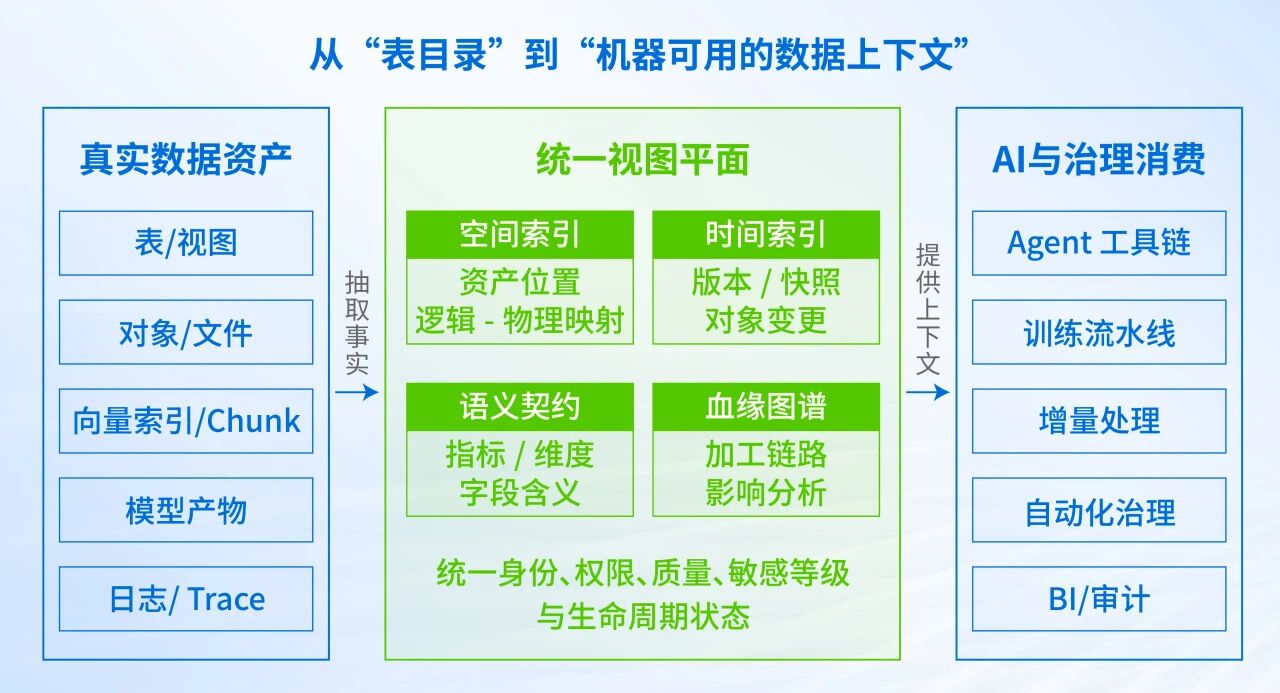
AI 数据湖统一视图总体架构
AI 工作负载改变数据资产的形态
在传统数仓和 BI 场景中,数据资产通常有一条比较清晰的路径:数据进入湖区,经过 ETL 或 ELT,被整理成表,再注册到 Catalog,最后被 SQL、报表或下游任务消费。
在这个路径里,Catalog 以表为中心是合理的。但 AI 工作负载让数据资产的形态变得更复杂。
模型训练:大量关键资产首先以文件和对象存在
模型训练和算法工程中的很多资产,最初并非以表格式存在:
-
原始语料:PDF、HTML、JSONL、图片、音频、视频。
-
训练产物:Checkpoint、Adapter、Tokenizer、评测结果。
-
检索数据:Embedding 文件、向量索引、Chunk 中间结果。
-
标注数据:人工审核样本、纠错样本、偏好数据。
-
推理数据:Prompt 日志、Response 日志、Trace、反馈记录。
这些数据非常关键,但未必进入正式 ETL,也未必有稳定 Schema,甚至未必会被立刻注册到计算层 Catalog。
所以,模型训练场景首先出现的是资产可见性问题:如果 Catalog 只覆盖已注册表,它就无法完整反映和利用 AI 工程中的真实数据资料。
Agent 推理:数据地图从“给人看”变成“机器用”
Agent 场景进一步改变了数据消费方式。对 Agent 来说,Catalog 不只是“能否查到一张表”,而是“在运行时能否形成可靠的数据上下文”。
人类工程师可以等待日报、查看监控、询问同事,也可以凭经验判断某个目录或任务状态。但是,Agent 没有这种组织记忆,只能依赖运行时可访问的上下文和工具来做决策。
更关键的是,Agent 消费数据的方式并非单点查询,而是一连串动作:理解任务→选择数据源→检索上下文或生成 SQL→调用工具→根据结果决定下一步。这个过程至少依赖三类判断:
-
选什么数据:有哪些表、文件、对象、日志、索引、模型产物可作为候选输入。
-
用哪个版本:这些数据是否最新,是否被替换、删除、覆盖,是否仍处于可用状态。
-
能不能正确使用:字段和状态码的含义,权限、敏感等级、生命周期状态和下游影响是什么。
例如,一个数据分析 Agent 要回答“最近一周某类客户投诉是否与版本发布有关”。它不能只知道有一张工单表,还需要找到发布记录、日志导出、客户标签、相关向量索引或文档;确认这些资产是否最新;理解字段、状态码和时间语义;判断哪些数据可访问,哪些数据因权限或敏感等级不适合当前任务。
这正是 Agent 场景需要统一视图的原因:它必须把空间、时间、语义和血缘放在同一个决策上下文中。如果元数据地图过旧,Agent 在推理或工具调用过程中就可能作出错误判断。

传统 Catalog 体系存在三个断层
由此可见,现有 Catalog 体系并非无效,而是在 AI 场景下存在三个关键断层。
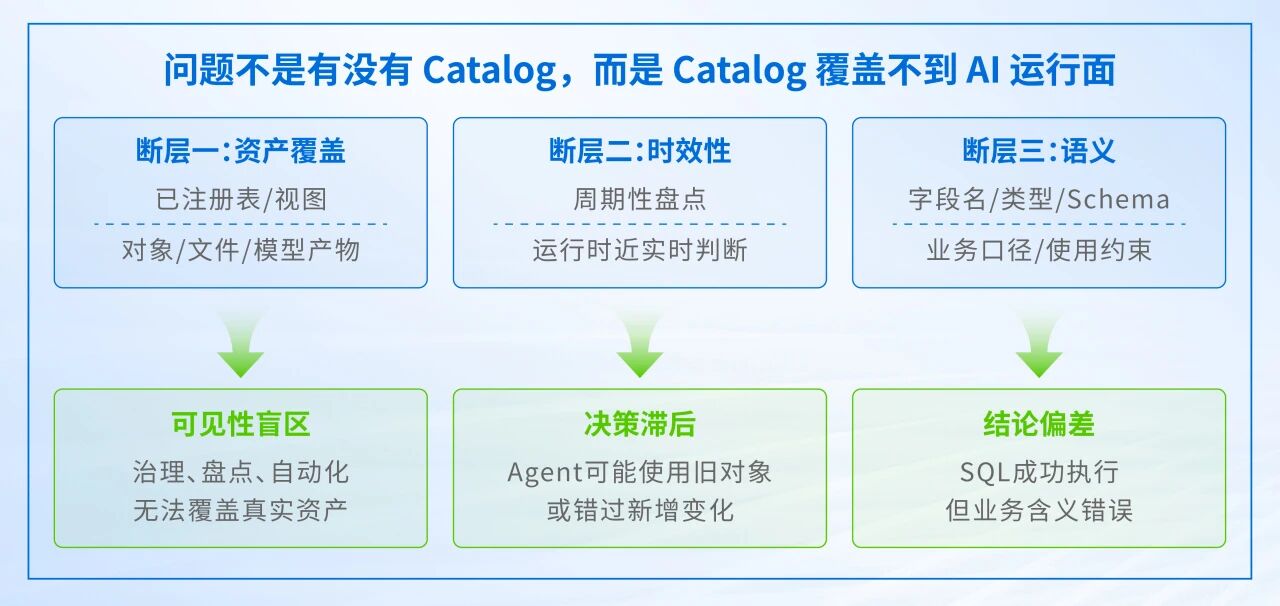
断层一:已注册资产与真实存储资产之间的断层
计算层 Catalog 通常只看到已被建模、注册、治理过的数据资产,比如表、视图、外部位置或数据产品。但存储系统中真实存在的数据远不止这些。
AI 数据湖中充斥着大量尚未建模的数据:原始语料、中间产物、模型文件、索引文件、日志文件、临时实验数据、标注样本。这些资产暂时可能不是表,但它们已经是数据湖的一部分。如果 Catalog 无法看见它们,那么治理、盘点、增量处理和自动化工作流都将出现盲区。
断层二:批量盘点与运行时决策之间的断层
很多元数据能力本质上是周期性盘点——每隔一段时间扫描一次对象、文件或表状态,然后生成清单。这对人工报表和定期治理有价值,但对运行时决策远远不够。
Agent、自动化治理任务、增量处理流水线更关心的是:最新有哪些对象新增了?哪些标签、权限或生命周期状态发生了变化?这些信息必须实时或近实时地支撑决策。
断层三:技术 Schema 与业务语义之间的断层
即使数据已经注册成表,Schema 也不等于语义。
一个表里有 ts / status / amt,人类工程师或许知道它们的意思,但是模型或 Agent 可能猜错:
-
ts 是事件时间,还是写入时间?
-
status = 1 是成功,还是启用?
-
amt 是订单金额,还是退款金额?
这类错误不一定会导致 SQL 执行失败,但会导致业务结论错误。因此,Catalog 不能只回答“字段叫什么”,还必须逐步回答“字段意味着什么、适合什么场景、不适合什么场景”。
AI时代的数据视图需要回答四个问题
将前文提到的三个断层合并来看,AI 数据湖需要的并不是一个更大的表目录,而是一套更完整的数据视图。这套视图至少需要回答下面四个问题。
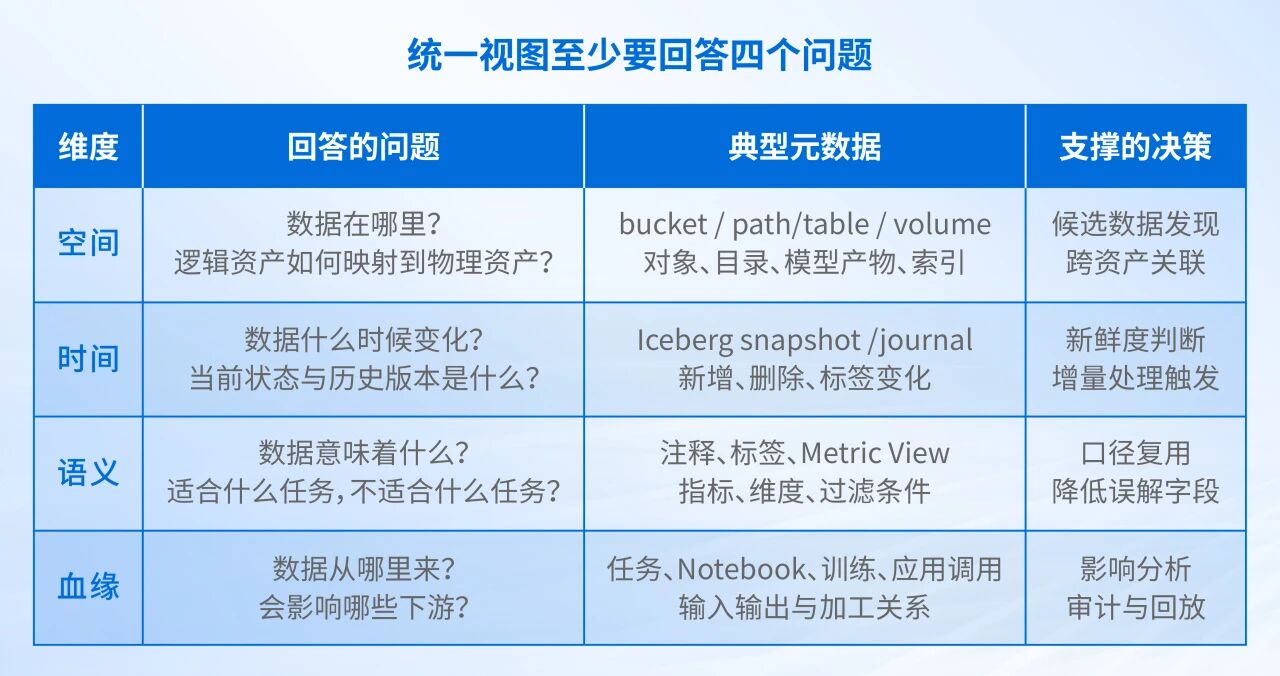
空间:数据在哪里?
这不仅包括表在哪里,也包括对象、文件、目录、模型产物、非结构化资产在哪里。
数据视图需要将逻辑资产和物理资产连接起来:既能看到被建模的数据产品,也能看到尚未建模但已经存在的数据对象。
时间:数据什么时候变化?
AI 数据湖既需要知道“当前有什么”,也需要知道“刚刚发生了什么”。
表格式(如 Apache Iceberg )能够提供表级快照、版本历史和 Time Travel 能力,解决的是“某张表在某个版本是什么状态”的问题。
对象和文件层面的变化日志解决的是另一类问题:哪些文件被创建、更新或删除;哪些对象标签、用户元数据信息发生变化。
两者粒度不同,但都属于时间视图的一部分。
语义:数据意味着什么?
语义视图回答的是:这份数据在业务上是什么意思,适合什么任务,不适合什么任务。
其核心不是“给字段写几句说明”,而是把业务口径变成可治理、可复用、可被机器消费的对象。这可以从三个层面来理解:
第一层:自然语言说明
主要帮助人和LLM理解上下文。表、视图、列的业务描述,枚举值和状态码解释,事件时间、处理时间、入湖时间等时间语义,都适合用文档化描述表达。
第二层:结构化约束
主要帮助系统和规则引擎进行过滤、授权和风险判断。敏感等级、数据域、质量等级、使用约束、do_not_use_for 等信息,最好进入 TAG、属性或类似的结构化字段。
第三层:业务语义对象
View、Metric View 这类对象将指标、维度、过滤条件、JOIN 关系和业务口径封装成统一契约,让下游报表、自然语言查询和 Agent 复用同一套定义。
Databricks 的演进路径正是第三层的典型体现。Unity Catalog 本身已提供统一命名空间、权限、表和列注释、标签、信息模式和血缘等治理能力。在此基础上,Databricks 进一步将业务语义推向 Catalog 层,其代表性能力是 Unity Catalog Metric Views。Databricks 官方文档称其为 Unity Catalog Business Semantics 的核心实现。
以收入指标为例,很多企业都有多个收入口径——是否扣除退款、是否含税、是否只看已完成订单、按下单时间还是支付时间统计。如果这些规则散落在不同报表、SQL 和 Notebook 中,同一个问题很容易得出不同答案。
Metric View 将这些规则收回到 Unity Catalog 中进行统一定义。它就像一张带有业务规则的视图:底层仍然读取表、视图或 SQL 查询,但会明确写出收入如何计算、哪些记录需要过滤、可以按哪些维度分析,以及事实表和维表如何关联。
使用时,用户无需重新编写收入公式,只需调用已定义好的指标,再选择按时间、区域、渠道等维度查看。如此一来,BI 报表、自然语言查询和 Agent 面对的就不再是一堆字段名,而是一套可复用的业务口径。
这背后的路径判断是:语义层正在从“下游工具中的约定”回归到“统一治理平面中的一等对象”。
血缘:数据从哪里来,影响哪里?
血缘视图回答的是:这份数据来自哪里,被哪些任务处理过,影响哪些下游表、模型、报表或应用。血缘负责影响分析、审计、回放和质量追踪。
存储侧轻量视图:统一视图的起点
AI 数据湖需要统一视图,但这并非一个单点系统就能完成,也不可能只靠某个 Catalog 产品就能一蹴而就。空间、时间、语义、血缘分别来自不同层:
-
存储系统知道真实资产是否存在;
-
表格式知道表的版本和快照;
-
治理平台掌握权限和审计;
-
语义层定义业务口径;
-
血缘系统负责加工链路和影响范围。
因此,构建统一视图是AI时代数据基础设施建设的关键目标,也是一项长期工程。其难点不在于多存一些元数据,而在于让不同层的元数据对齐:同一个对象、文件、表、索引、模型产物能被识别为同一条资产链路;对象变化、表快照、任务运行和业务口径变更能被放在同一个时间上下文;权限、质量、敏感等级和使用约束能被机器读取;血缘还需跨越 ETL、Notebook、模型训练、检索索引与应用调用。
在统一视图中,语义固然重要,但语义并非凭空生成的。它首先需要一个稳定的事实底座:真实存在什么资产,位于哪里,什么时候新增、更新、删除,哪些基础元数据可供查询。缺乏这层事实底座,上层 Catalog 只能解释已经注册过的表,无法覆盖大量尚未建模但实际存在的 AI 数据资产。
这也是统一视图需要从存储侧起步的原因。企业数据首先存在于真实存储系统中,常常分散在 NAS、对象存储、文件共享和归档环境中。其中许多文件、对象、日志、模型产物尚未注册为表,却已经被训练、检索、治理任务和 Agent 流程使用。没有面向异构存储数据的统一纳管,上层 Catalog 只能围绕已登记对象工作,难以完整覆盖真实资产、基础权限和变化状态。
因此,存储侧轻量视图的前置价值主要体现在两个方面:
使异构存储中的真实数据先被看见
NAS 目录、对象 Bucket、文件共享、日志和模型产物可以被统一纳管为可查询的资产事实,避免统一视图只覆盖已经建模或登记的数据。
使所需数据可以被快速定位
通过空间索引记录文件、对象和目录的位置、类型、标签、时间状态和授权关系,Agent 可以直接查询候选数据的位置与状态,而不是对异构存储做全局遍历,从而缩短检索时间,降低对存储系统的影响范围,提升运行时决策效率。它不替代 Catalog、治理、血缘或语义系统,而是为这些系统提供共同事实入口,使统一视图从真实存在的数据出发,而不是只从已建模数据出发。
因此,相对合理的路径是:先在存储侧建立轻量视图,清晰看见真实资产和变化;再将这层事实底座接入治理、血缘和语义系统,逐步走向“理解数据”。
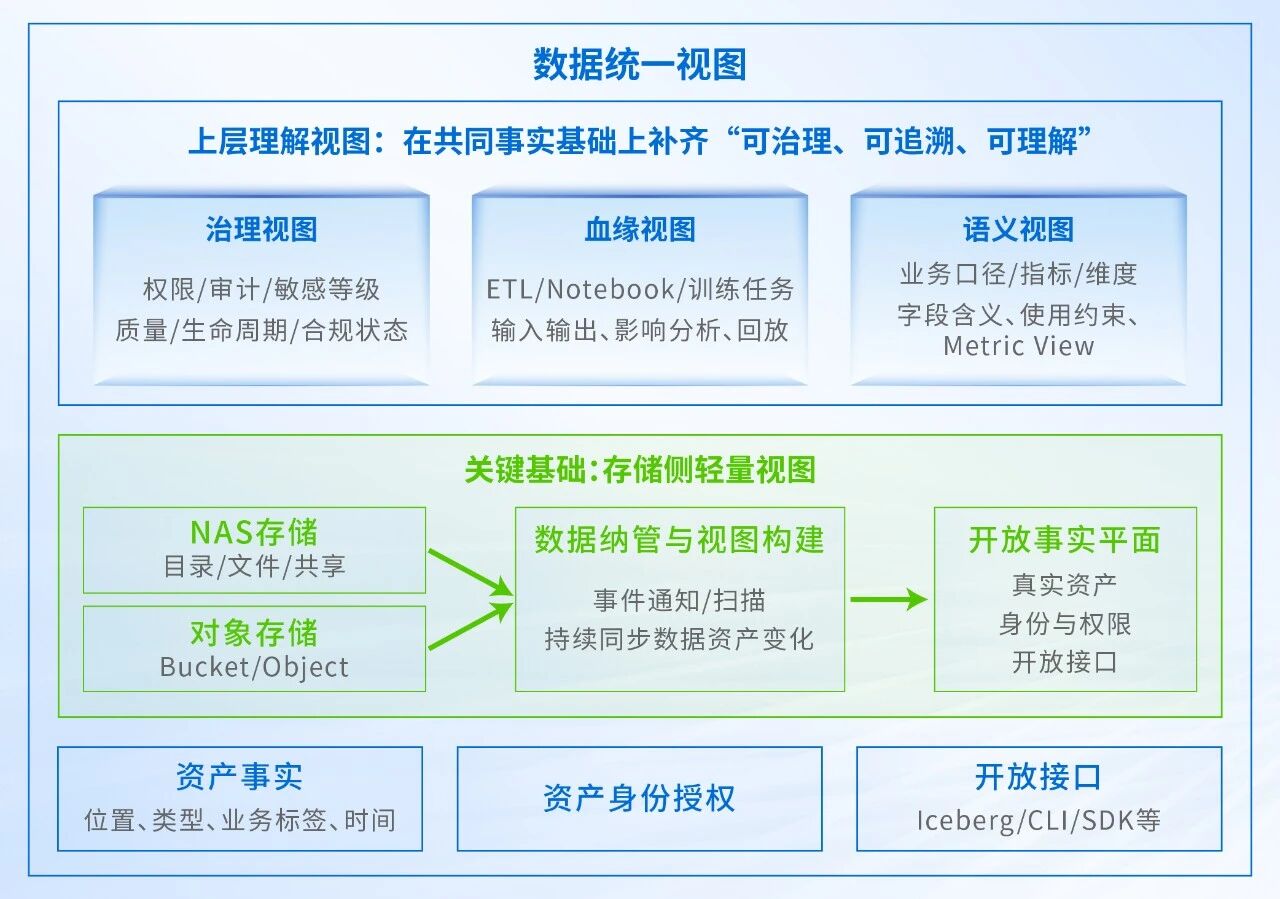
建议存储侧轻量视图做好以下三项基础工作:
-
资产事实层:持续呈现对象、文件、目录、模型产物、日志、索引等真实资产的位置、大小、类型、标签、用户元数据和基础状态。
-
变化事实层:近实时更新新增、删除、标签变化、用户元数据变化、存储类别相关变化,让治理任务和 Agent 能看到“刚刚发生了什么”。
-
开放消费层:通过 Iceberg 等开放表格式或兼容查询接口,将这些基础事实开放给计算引擎、治理平台、血缘系统和 Agent 工具链,而非锁在存储系统内部。
在此基础上,治理和语义系统继续补齐剩下的问题:
-
治理层负责将资产事实接入权限、审计、质量、敏感等级和生命周期管理;
-
血缘层负责将存储资产、计算任务、表、模型、报表和应用串联起来;
-
语义层负责将字段、指标、维度、过滤条件、JOIN 关系和业务口径结构化。
存储侧的轻量视图不是终点,而是让上层系统拥有共同事实基础的起点。
扫码获取一对一服务

关注我们
关于我们


关于我们
扫码获取一对一服务

